Srpski / Arhiva brojeva / PRVI BROJ / prof. dr G. LUKATELA: O osobinama jezika koje utiču na kvalitet telekomunikacionih poruka
O osobinama jezika koje utiču na kvalitet telekomunikacionih poruka
Georgije Lukatela
SADRŽAJ
U ovom članku razmatraćemo neke manje poznate osobine našeg jezika koje mogu da utiču na prenos, brzinu obrade i prepoznatljivost pisanih telekomunikacionih poruka. Tako, na primer, pokazuje se da mozak najefikasnije obrađuje one poruke koje sadrže 7 ili manje „odvojivih elemenata“ informacije; takođe se pokazuje da „štamparske greške“ u obliku premeštenih slova, uz izvesna ograničenja, ne uništavaju razumljivost pisane poruke; članak ističe činjenicu da misaoni procesi koriste apstraktne fonološke kodove, što znači da svaka fonološka neodređenost u pisanoj poruci može da dovede u pitanje razumljivost primljene poruke.
U posebnim slučajevima, kada se pisane poruke prikazuju izuzetno kratko (na primer, u podnaslovima stranih filmova ili kod prevoda razgovora sa strancima „uživo“ na TV, itd.) i kada korisnik informacija ne može sa sigurnošću da identifikuje ni fonološki jednoznačne reči, dolazi do pojave nenamernog primovanja vizuelno sličnim rečima koje je korisnik video u nekoj prethodnoj poruci. Takvo nenamerno primovanje moglo bi ozbiljno izmeniti smisao primljene poruke. Srećom, postoji jednostavan način da se nenamerno primovanje izbegne: prikazivanje poruke treba produžiti onoliko koliko je potrebno da slovni znaci u svakoj poruci postanu pouzdano prepoznatljivi.
Zahvaljujući jednostavnosti našeg fonetskog pravopisa, veliki deo našeg školovanog stanovništva ume da čita kako ćirilicu tako i latinicu. Postojanje bialfabetskih čitalaca svakako je sretna okolnost za našu kulturu i civilizaciju, ali ono nam donosi i svojevrsne probleme o kojima govori ovaj članak.
OSNOVNI MODEL DIGITALNOG PRENOSA PORUKA
Na Slici 1. šematski smo predstavili osnovni model digitalnog prenosa poruka uz korišćenje binarnog kanala. Takav kanal koristi samo dva kodna znaka, „nulu“ i „jedinicu“. U posmatranom modelu prenosa kognitivni (tj. misaoni) sistem jednog čoveka predstavlja izvor informacija, a kognitivni sistem drugog čoveka predstavlja korisnika informacija.

Slika 1. Blok-šema digitalnog prenosa poruka
Da bismo raspoloživi prenosni kanal efikasnije koristili, potrebno je da kanal sa svoje ulazne strane bude prilagođen izvoru informacija, a sa svoje izlazne strane - korisniku informacija. Situacija je donekle slična onoj kod prenosa električne energije posredstvom visokonaponskog kabla, kada - u cilju smanjenja prenosnih gubitaka - prilagođavamo impedansu izvora energije impedansi kabla, a impedansu kabla impedansi potrošača energije. U slučaju prenosa jezičkih informacija, prilagođavanje „izvor - prenosni put“ vrši se statističkim kodovanjem. Teorija informacija nas uči da, u proseku, najveću količinu informacija generiše onaj izvor koji stvara jednako verovatne simbole (Lukatela, 1981). Takav izvor za korisnika predstavlja najveću prosečnu neizvesnost (tj. najveću „entropiju“), a svaki simbol takvog izvora u proseku donosi korisniku najveći mogući broj šenona (tj. jedinica za količinu informacija). Entropija simetričnog binarnog izvora informacija bez memorije iznosi ld (m), pri čemu „m“ označava ukupni broj jednako verovatnih simbola sa liste izvora, a ld je logaritam za osnovu 2. Pošto naš ćirilički alfabet sadrži 30 slova (grafema), entropija našeg pisanog teksta iznosila bi oko 5 šenona po primljenom slovu, pod idealizovanom pretpostavkom da su sva slova u tekstu jednako verovatna i međusobno statistički nezavisna. Međutim, u realnom tekstu neka slova srećemo češće, a neka ređe; pored toga, između pojedinih slova postoji statistička zavisnost, jer se foneme grupišu u skladu s propisima naše ortografije i fonetike. Na primer, u našem tekstu slovo A pojavljuje se mnogo češće nego slovo H, a slovo F nikada se ne pojavljuje neposredno posle slova Z, itd. Zbog takvih statističkih ograničenja, slovni znaci ne nose maksimalnu moguću količinu informacija, a njihov prenos telekomunikacionim kanalom možemo da uporedimo s prevozom polupraznih, nedovoljno natovarenih vagona u železničkom transportu. Očigledno, da bi učinili prevoz robe ekonomičnijim, železničari će izvršiti pretovar robe kako bi istu količinu robe preneli manjim brojem dobro natovarenih vagona, ili će za prevoz koristiti veći broj manjih vagona koji bi datom robom bili natovareni do granice nosivosti. Zamena simbola, odnosno „pretovar“ prosečne količine informacija, ostvaruje se postupcima statističkog kodovanja koje se zasniva na poznavanju verovatnoće pojavljivanja pojedinih slova, kao i na činjenici da slova koja se češće pojavljuju nose manju količinu informacija, i obratno. Zato je najekonomičnije da česte simbole izvora informacija zamenimo novim, kratkim kodnim znacima, a da retke simbole izvora informacija zamenimo novim, dužim kodnim znacima, baš onako kako se to radilo u klasičnoj telegrafiji pomoću Morzeovih znakova. Na prijemnoj strani prenosnog sistema nalazi se statistički „dekoder“ koji vrši obratni „pretovar“ informacija. Umesto privremenih, novih kodnih znakova, na izlazu prenosnog kanala dekoder vraća stare, prirodne simbole. To vraćanje je neophodno da bi vizuelni sistem korisnika informacija bilo u stanju da prepozna originalnu pisanu poruku.
Na osnovu prethodno rečenog, možemo da pretpostavimo da projektovanje ekonomičnog prenosa poruka zahteva bar neko elementarno poznavanje prirode govora i kognitivnih procesa u mozgu čoveka.
BLOK-ŠEMA PROCESA ČITANJA
Blok šema procesa čitanja štampanih reči prikazana je na Slici 2. Dvodimenzionalna slika koju čovečje oko „snimi“ tokom jedne fiksacije oka (tj. tokom jedne „sakade“) čuva se u „ikoničnoj“ memoriji na retini oka. Snimljene slike ostaju u ikoničnoj memoriji u neobrađenom stanju i u originalnom dvodimenzionalnom prostornom rasporedu.
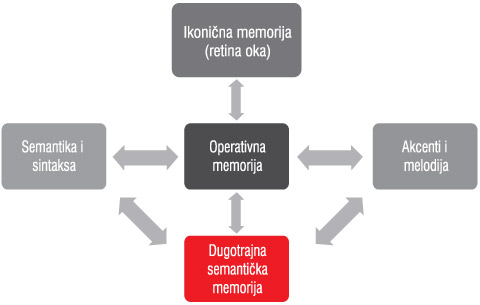
Slika 2. Osnovna blok-šema procesa čitanja
Boljem razumevanju kognitivnih procesa na ikoničnoj memoriji, posebno su doprinela dva komplementarna eksperimenta: prvi je bio eksperiment „parcijalnog izveštavanja“, a drugi je bio eksperiment „totalnog izveštavanja“. U oba eksperimenta, na ekranu monitora ispitaniku se kratkotrajno (do 100 ms) prikazuje skup od 18 različitih štampanih slova koja su raspoređena u obliku prostorne, dvodimenzionalne matrice sa 3 reda i po 6 slova u svakom redu. Ispred ispitanika leže pripremljeni listovi papira sa ucrtanim malim, praznim kvadratima, koji svojim rasporedom na hartiji definišu prostornu matricu sa 3 reda i sa po 6 praznih kvadrata u svakom redu. Tako nacrtana matrica kvadrata imala je isti oblik kao i slovna matrica koju je ispitanik prethodno video na ekranu monitora.
U ogledu parcijalnog izveštavanja, odmah posle kratkotrajnog prikazivanja slovne matrice, ispitanik je u slušalicama čuo jedan od tri tona: visoki, srednji, ili niski. Zadatak ispitanika je bio da srazmerno visini tona usredsredi svoju pažnju prema gornjem, prema srednjem, ili prema donjem redu zapamćene slovne matrice, te da što brže na pripremljenom listu hartije upiše zapamćena slova iz naznačenog reda slovne matrice u odgovarajući red matrice kvadrata. Rezultat ogleda parcijalnog izveštavanja pokazuje da je ispitanik tačno upisivao u proseku oko 4 slova. Pošto ispitanik nije mogao unapred da zna iz kojeg će reda slovne matrice on morati da daje izveštaj, logično je pretpostaviti da je ispitanik iz svakog reda pamtio po 4 slova, što čini ukupno 4 x 3 = 12 upamćenih slova.
Zadatak ispitanika koji je učestvovao u eksperimentu totalnog izveštavanja bio je nešto drugačiji. On nije imao slušalice za slušanje tonova, nego je bio upućen da odmah posle prikazivanja slovne matrice (potpuno jednake onoj u zadatku parcijalnog izveštavanja) u nacrtane prazne kvadrate upiše sva slova koja je malo pre video na ekranu monitora. Moglo se očekivati da će ispitanik u ogledu totalnog izveštavanja ponoviti teorijski rezultat parcijalnog izveštavanja, tj. da će upisati oko 12 upamćenih slova. Međutim, rezultat je bio samo 5 pravilno upamćenih slova, što je bilo znatno manje od očekivanog broja. Zaključak je bio da iščitavanje slova iz ikonične memorije odnosno obrada tih slova u kratkotrajnoj, operativnoj memoriji imaju ograničeni kapacitet koji iznosi 7 ili manje slova. U nekim drugim eksperimentima potvrđeno je da je mogućnost simultane obrade u kratkotrajnoj memoriji, po pravilu, ograničena na 7 (ili manje od 7) „odvojivih elemenata“ informacije. Pri tome, jedan „odvojiv element“ informacije najčešće predstavljaju slovo, grupa slova, kratka reč, jedna cifra, ili grupa cifara. Ovaj rezultat želimo da pojasnimo. Kada čovekov mozak usmeri vektor pažnje prema ikoničnoj memoriji, tada započinje proces iščitavanja i prebacivanja uočenih elemenata informacije u operativnu memoriju. Tokom jedne očne fiksacije, vektor pažnje u stanju je da obuhvati i prebaci u operativnu memoriju 7 ili manje odvojivih elemenata informacije. Zato se kaze da za operativnu memoriju broj 7 predstavlja „magični broj“. Verovatno zbog tih svojstava operativne memorije, u telefonskim mrežama lokalni telefonski brojevi pretplatnika retko sadrže preko 7 cifara. Kada je telefonski broj duži od 7 cifara, mi ga nesvesno delimo na dva dela, tj. na dva nova elementa informacije, svaki element sa manje od 8 cifara.
U kratkotrajnoj, operativnoj memoriji od učitanih slova grade se reči koje se identifikuju procesom pretraživanja fonološkog leksikona. Od skupa reči - pod kontrolom gramatičkog i sintaktičkog bloka - gradi se rečenica. Postoje jake eksperimentalne indicije da se svi kognitivni procesi u operativnoj memoriji kao i u dugotrajnoj memoriji odvijaju na bazi apstraktnih fonoloških kodova (Lukatela, Eaton, Moreno & Turvey, 2007). U završnoj fazi procesa čitanja - uz pomoć prozodijskog bloka - određuju se akcenti reči i melodija rečenice. Brzina celokupnog procesa prepoznavanja, odnosno čitanja reči, uveliko će zavisiti kako od frekvencije javljanja pojedinih reči u jeziku, tako i od asocijativne povezanosti tih reči. Naime, pretpostavlja se da je dugotrajni leksikon građen po principu frekvencijskog raspoređivanja i semantičke bliskosti. To znači da će frekventnije reči (tj. one reči koje se češće upotrebljavaju u jeziku) biti locirane u apstraktnom prostoru u blizini ulaza u dugotrajni leksikon, a da su retke, manje frekventne reči locirane daleko od ulaza u dugotrajni leksikon. Razume se, pronalaženje i kontaktiranje reči u dugotrajnoj memoriji zavisi od „udaljenosti“ pojedinih reči od ulaza u leksikon. Očigledno, što je kraća apstraktna udaljenost tražene procesne jedinice, to je brže pronalaženje te reči u leksikonu. Logična je pretpostavka da u dugotrajnom leksikonu između semantički bliskih odnosno asociranih reči postoje snažnije pobudno-inhibitorne veze nego li između semantički dalekih odnosno neasociranih reči. Kada neka reč - koju obrađujemo u operativnoj memoriji - u dugotrajnom leksikonu pobudi jednu ili više asociranih odnosno semantički povezanih reči, onda obrada u kratkotrajnoj memoriji može biti ili ubrzana ili usporena. Obrada će biti ubrzana ako u dugotrajnom leksikonu sve aktivirane reči doprinose jednoznačnom određivanju trenutno obrađivane reči. U protivnom, proces prepoznavanja reči u operativnoj memoriji može biti usporen.
SIMULACIONI MODEL PREPOZNAVANJA I ČITANJA REČI
Prema savremenim shvatanjima, kognitivni proces identifikacije i čitanja reči odvija se u lancu od nekoliko interaktivno povezanih procesa. Uobičajeno je da se ti procesi dele na predleksičke (tj. procesi koji se odvijaju pre uspostavljanja kontakta s leksikonima), leksičke (tj. procesi koji se dešavaju u interakciji ulazne pobude i kratkotrajnog ortografskog i fonološkog leksikona), te asocijativno-semantičke i prozodijske procese. Najzad, postoje i razni integrativni kognitivni procesi koji ujedinjuju funkcije govora s drugim funkcijama čoveka kao misaonog bića. Samo dva prvopomenuta tipa procesa (predleksički i leksički) do danas su bolje ispitani i provereni simulacijama uz pomoć računara. Jedan od poznatijih simulacionih modela za vizuelno prepoznavanje reči potiče od Colthearta i njegovih saradnika (2001). Prema „teoriji dvojnog puta“ koju je Coltheart (1978) predložio da bi objasnio čitanje izolovanih štampanih reči, ulazna informacija o pročitanoj reči ulazi u čovekov kognitivni sistem posredstvom dva, paralelna pristupna puta. Jedan put vodi direktno ka ortografskom leksikonu, pa je zato dobio ime „direktni” ili „leksički put”. Drugi, zaobilazni put, preko neleksičkog bloka za konverziju grafema u foneme, vodi do fonološkog leksikona i do izlaznog fonemskog bloka. Taj zaobilazni put Coltheart je nazvao „indirektnim” ili „neleksičkim”, a svom simulacionom modelu dao je ime „Model dvojnog puta”, ili skraćeno: „DRC-model” (od engleskog: “The Dual-Route Continuous Model”). Prema simulacionom modelu dvojnog puta (Slika 3), ulaznu pobudu predstavlja štampana reč, dok auditivni izlaz modela čini fonetska predstava reči koja odgovara vizuelnoj pobudi.
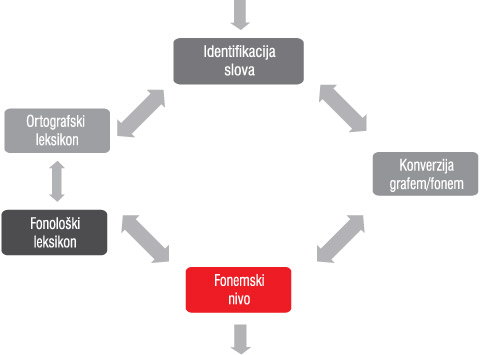
Slika 3. Blok šema modela za simulaciju prepoznavanja i čitanja reči
Glavne elemente leksičkog spojnog puta čine dva kratkotrajna leksikona: ortografski i fonološki, a glavni deo neleksičkog spojnog puta čini konvertor grafema u foneme. Konverzija se vrši na osnovu pravila korespondencije grafema i fonema. Ortografski leksikon sadrži ortografske predstave svih jednosložnih reči dužine do 8 slova, a fonološki leksikon sadrži kompletne fonološke predstave istih reči. Kratkotrajni ortografski leksikon sadrži „ortografske procesne jedinice”, a kratkotrajni fonološki leksikon sadrži „fonološke procesne jedinice” jezika. U modelu dvojnog puta, po jedan par komplementarnih ortografskih i fonoloških procesnih jedinica predstavlja jednu određenu reč u vizuelnom i u auditivnom domenu; svaki takav par procesnih jedinica međusobno je spojen dvosmernim (pobudnim i inhibitornim) vezama. Tako se obezbeđuje puna interakcija dvaju leksikona. Pobuda procesnih jedinica u ortografskom leksikonu - preko ortografskog konvertora tipa „slovni znak/grafem”, - dolazi od ulaznog niza slova koja čine ulaznu reč. Na ovom mestu primećujemo da u našem pismu postoji potpuna jednakost između pojma „slovni znak“ i pojma „grafem“, te za naš jezik konverzija tipa „slovni znak/grafem” uopšte nije potrebna. Nastavljajući opis pobude ortografskih procesnih jedinica, treba istaći da će u ortografskom leksikonu biti pobuđen samo onaj grafem koji se nalazi na istoj rednoj poziciji, kako u nizu grafema koji predstavljaju datu procesnu jedinicu, tako i u nizu grafema koji predstavlja ulaznu štampanu reč (redni broj pozicije računa se polazeći od prvog slova na krajnjoj levoj strani štampane reči). Kada za neku ortografsku procesnu jedinicu nastane potpuna podudarnost grafema (na svim pozicijama procesne jedinice i ulazne štampane reči), onda će ta ortografska procesna jedinica postati maksimalno pobuđena već posle manjeg broja iteracija.
Originalni DRC model bio je projektovan da objasni vizuelno prepoznavanje engleskih reči za koje je leksički put brži i efikasniji od neleksičkog puta. Ta činjenica uzimana je kao dokaz o superiornosti leksičkog puta nad neleksičkim putem, a prema tome i o superiornosti ortografije nad fonologijom. Međutim, originalni DRC-model nije zadovoljio, kada smo mi simulirali engleske oglede čitanja uz korišćenje „pseudohomofona“, tj. specijalnih nereči koje zvuče kao engleske reči (napomena: za engleski jezik svaki niz slova koji ne postoji u ortografskom rečniku predstavlja jednu „nereč“, bez obzira kako takav niz slova zvuči). Da bismo osposobili DRC-model da simulira naše eksperimente, mi smo originalne parametre DRC-modela zamenili novim parametrima koji su ubrzali procese aktivacije u fonološkom leksikonu. Tako modifikovani model uspešno je simulirao naše eksperimente rezultate, pokazujući da hipoteza o prednosti ortografije nad fonologijom nije uvek tačna (Lukatela, Eaton, Lee, Carello & Turvey, 2002).
O NAŠEM PRAVOPISU
Ako pogledamo strukturu naše ćirilice i latinice, uočavamo da oba alfabeta sadrže tri klase velikih slova: (1) zajednička velika slova koja se jednako izgovaraju u oba alfabeta (na primer, A, K,..), (2) zajednička velika slova koja se različito izgovaraju (na primer, veliko slovo P izgovara se kao fonem /p/ u latinici, a kao fonem /r/ u ćirilici), te (3) specifično ćirilička ili specifično latinička velika slova (na primer, D, F ...) koja se koriste ili samo u ćirilici, ili samo u latinici. Razume se, alfabetski specifična slova ćirilice i latinice nikada se ne pojavljuju izmešana u istoj reči.
S teorijskog stanovišta, problem bialfabetskog čitanja obuhvata pitanje međusobnog odnosa našeg ćiriličkog i latiničkog alfabetskog sistema. Mi smo tom problemu pristupili eksperimentalnim putem (Lukatela, Savić, Ognjenović i Turvey, 1978.). U našim ogledima koristili smo obrazovane mlade ljude, studente Elektrotehničkog fakulteta u Beogradu, koji su prethodno pokazali da su dobri bialfabetisti, tj. da podjednako dobro koriste oba alfabeta: latinicu i ćirilicu. Bialfabetizam naših studenata-ispitanika doneo je sa sobom i neke probleme koji su specifični za našu populaciju čitalaca. Na primer, kada bialfabetski čitalac naiđe na štampanu reč POTOP, čitaočev vizuelno/auditivni sistem dekodovanja može automatski da generiše više fonoloških predstava: /potop/, /rotor/, /potor/ i /rotop/, pri čemu su prve dve dobro poznate reči našeg jezika. Zbog toga, može se očekivati da će štampane reči poput POTOP izazvati usporavanje procesa čitanja, a moguće je da će dovesti i do pogrešne semantičke interpretacije primljene poruke. Međutim, a priori nije jasno, u kakvom su međusobnom odnosu alfabetski sistemi u mozgu bialfabetskog čitaoca. Postoje dve verovatne konfiguracije: (i) svaki alfabet predstavlja jedan nezavisan sistem, (ii) jedan alfabet predstavlja nadređeni sistem, dok drugi alfabet predstavlja podređeni sistem.
Da bismo razjasnili koja je od te dve konfiguracije bliza stvarnom stanju u mozgu, izvršili smo prost ogled. Našim bialfabetskim ispitanicima, na ekranu monitora bila su prikazana pseudoslučajnim redom različita ćirilička i latinička slova. Zadatak ispitanika bio je da što brže pritiskom na jedan od dva tastera (jedan za odgovor DA; drugi za odgovor NE) odgovori na pitanje: „Da li je prikazano slovo ćiriličko?” ili na pitanje: „Da li je prikazano slovo latiničko?“ Merenjem vremena odgovora ustanovili smo da onaj student koji je u osnovnoj skoli prvo učio ćirilicu, u ogledu je sporije potvrđivao da neko od zajedničkih slova (na primer, M, ili T, ili K, ..) pripada latinici, a brže je potvrđivao da to slovo pripada ćirilici. Isti student je sporije potvrđivao da je neko specifično slovo latinice (na primer, D, ili F, ili S, ..) zaista latiničko. Komplementarna slika odgovora dobijena je od ispitanika koji su u osnovnoj skoli prvo naučili latinicu. To znači da je redosled učenja alfabeta u detinjstvu ostavlja u mozgu neizbrisive tragove. Zaključili smo da je prvo-naučeni alfabet poslužio kao osnovni sistem na koji je naknadno nadograđen drugo-naučeni alfabet.
BIALFABETSKO ČITANJE
Na početku istraživanja bialfabetskog čitanja (Lukatela, Savić, Gligorijević, Ognjenović i Turvey, 1978.) pretpostavili smo da čitanje nekih alfabetski kritičnih reči (kao što je na primer, reč BETAP) može biti teže nego čitanje iste te reči u drugom alfabetu (kao što je to VETAR), jer fonološki dvoznačna slova B i P tokom čitanja kritičnih reči – ukoliko kritična reč ne sadrži i slova specifična za latinicu ili za ćirilicu - mogu da uspore proces ortografsko/fonemske konverzije. Međutim, slušajući golim uhom našeg bialfabetskog čitaoca, postalo je jasno da naš čitalac bez uočljive zadrške i bez zamuckivanja može lepo da čita i ćiriličku i latiničku verziju svake štampane reči. Naravno, postojala je sumnja da su ispitanici ipak usporeno čitali reči koje sadrže fonološke dvoznačnosti, ali usporavanje nije bilo dovoljno veliko da bi ga mogli zapaziti slobodnim slušanjem. Zato smo istraživanje nastavili korišćenjem osetljivije i pouzdanije merne metode. Odabrali smo poznati zadatak „leksičke odluke”. Kod tog zadatka, na ekranu monitora čitaocu se prikazuje niz od 5 do 10 velikih štampanih slova ćirilice ili latinice. Taj niz slova zove se „meta”, a s jednakom verovatnoćom predstavlja ili našu reč, ili – neku nereč (podsecamo da je „nereč“ onaj niz slova koji nije zapisan u rečniku i koji ispitanik nikada ranije nije video). Pritiskom na jedan od dva tastera ispitanik brzo odgovora na pitanje: „Da li je meta predstavlja neku našu reč?” Vreme leksičkog odgovora, tj. vreme reakcije ispitanika meri se od početka prikazivanja mete, pa do trenutka kada ispitanik pritisne taster. Tačnost merenja obično je bolja od 1 ms. U posmatranom ogledu nas nije interesovalo vreme reakcije kao takvo, nego nas je zanimala eventualna razlika u vremenu reakcije između odgovora na fonološki višeznačnu reč (poput reči BETAP) koju testiramo i odgovora na fonološki jednoznačnu reč (VETAR) koju koristimo kao kontrolu. Treba naglasiti da su test reč (BETAP) i odgovarajuća joj kontrolna reč (VETAR) identične u svakom pogledu (imaju isto značenje, iste asocijacije, istu frekvenciju, isti gramatički rod, isti padeški oblik, isti broj slova, itd., a jedinu razliku između testa i kontrole čini fonološka dvoznačnost. Prema tome, ako između test reči i kontrolne reči postoji pouzdana razlika u vremenu reakcije, moći ćemo sa sigurnošću da zaključimo da ta razlika potiče od fonološke dvoznačnosti. Statističkom analizom rezultata ogleda za različite tipove test-reči i odgovarajuće kontrolne reči, dobili smo pouzdan dokaz da svaka štampana test-reč koja sadrži fonološki dvoznačna slova usporava leksičku odluku u poređenju s kontrolom koja je fonološki jednoznačna.
U nastavku istraživanja bilo je utvrđeno da relativno usporavanje leksičke odluke zavisi od broja fonološki dvoznačnih slova. Tako, na primer, meta s jednim dvoznačnim slovom (MOTOP) prepoznaje se oko 25 ms sporije nego njena kontrolna reč (MOTOR) koja ne sadrži ni jedno fonološki dvoznačno slovo. Slično, meta koja sadrži 3 fonološki dvoznačna slova (na primer, HAHOC) usporava leksičku odluku za skoro 130 ms u odnosu na kontrolnu reč (NANOS). Ovi interesantni rezultati ukazuju da u našem jeziku fonologija i fonološko kodovanje igraju značajnu ulogu u procesu prepoznavanja i čitanja reči i da se naš jezik po tome bitno razlikuje od engleskog. Usporavanje fonološki dvoznačnih reči simulirali smo uz pomoć modifikovane verzije DRC-modela. Glavni element nove verzije modela bio je bialfabetski konvertor koji na početku procesa konverzije kao prvo identifikuje broj (N) dvoznačnih slova (B, C, H, ili P) u pobudnom nizu slova na ulazu u konvertora. Uvrstavanjem broja N u jednostavnu relaciju, 2exp (N), program određuje koliko će fonemskih nizova da generiše na izlazu konvertora kao odgovor na jedan ulazni niz slova. Na primer, kada štampana reč BETAP u neleksičkoj grani simulacionog modela pobudi bialfabetski konvertor, konvertor će prvo identifikovati da u pobudnom nizu slova postoje dva fonetski dvoznačna slova (N = 2). Na osnovu informacije da je N=2, konvertor će na svojoj izlaznoj strani generisati ukupno 2exp(2) = 4 niza fonema: /vetar/, /vetap/, /betar/, i /betap/. Prvi niz fonema /vetar/ predstavlja kontrolnu reč, dok ostala tri niza fonema predstavljaju nereči. Svaki niz fonema razlikuje se od prethodnog samo jednim fonemom, ali će svaki fonemski niz nepotpuno pobuditi različite procesne jedinice u fonološkom leksikonu. Potpunu pobudu svoje fonološke procesne jedinice može da ostvari samo konvertovana reč /vetar/, dok konvertovane nereči - /vetap/, /betar/ i /betap/ - ne mogu da nađu svoje procesne jedinice u fonološkom leksikonu. Proces lociranja konvertovane reči biće otezan činjenicom da će konvertovane nereči u leksikonu nepotpuno aktivirati mnoge druge procesne jedinice, koje će sa svoje strane inhibirati (tj. sprečavati) brzo aktiviranje procesne jedinice za reč /vetar/. Na suprot tome, kada na ulaz konvetora priključimo štampanu reč VETAR, na izlazu konvertora pojavice se samo jedan niz fonema (/vetar/) koji će u fonološkom leksikonu brzo locirati traženu reč. Time se može objasniti brže prepoznavanje fonetski jednoznačnih slovnih nizova. Da zaključimo: s porastom broja fonetski dvoznačnih slova (N), raste broj parcijalno aktiviranih procesnih jedinica u leksikonima, a takođe raste i inhibitorno delovanje konvertovanih nereči na proces lociranja i aktiviranja tražene reči – mete.
„PRIMOVANJE“, TJ. OLAKŠAVANJE PROCESIRANJA METE
Boljem razumevanju procesa prepoznavanja i čitanja reči, doprinela je metoda maskiranog „primovanja“ mete, pri čemu reč „primovanje“ označava olakšavanje procesiranja prikazane mete (Forster & Davis, 1984). Kao što smo već objasnili, u klasičnom ogledu „leksičkog odlučivanja“ ispitaniku se pokazuje „meta“ (tj. niz slova), a ispitanik mora brzo da odluči da li ta meta predstavlja reč ili nereč , tj. da li je prikazani niz slova zapisan kao reč u dugotrajnom leksikonu. Od momenta početka prikazivanja mete, u mozgu ispitanika započinje proces pretraživanja leksikona. Za česte reči, koje se nalaze blizu ulaza u dugotrajni leksikon, pretraživanje će brzo uspeti da locira traženu metu. Za retke reči pretraživanje će trajati duže. Za nereč , tj za niz slova koji ne postoji u leksikonu, pretraživanje će trajati najduže, jer tada se mora pretražiti celokupni leksikon . Proces pretraživanja može se bitno olakšati odnosno ubrzati postupkom primovanja. U tom postupku ispitaniku pre „mete“ pokazujemo „prim“ (tj. jedan drugi niz slova) koji može da olakša leksičko prepoznavanje mete. U opštem slučaju, prim se pokazuje ispitaniku neposredno pre mete, a može da predstavlja neku reč ili nereč . U specijalnom slučaju primovanja identitetom, prim i meta su dve identične reči ili dve identične nereči. U tom slučaju, na ekranu monitora ispitanik bi video sledeći redosled stimulusa Prvo, ispitanik vidi „prim“ (na primer, reč POTRES). Kratko vreme posle prima na ekranu se pojavljuje meta (u posmatranom primeru primovanja identitetom - to je ponovo reč POTRES); ta meta ostaje na ekranu sve dok ispitanik ne odgovori da li je POTRES neka naša reč ili nereč . Pošto je ispitanik video i registrovao prim, proces prepoznavanja mete nailazi na već pripremljeni teren pobuđenih spojnih puteva. Zahvaljujući toj pred-pobudi perceptivnog sistema identičnim primom, ispitanik može brzo i tačno da donese leksičku odluku da je POTRES naša reč. Očigledno, u slučaju primovanja identitetom, svi parametri koji definišu jednu leksičku jedinicu (vizuelna forma, ortografska i fonološka predstava, semantika, itd) jednaki su za prim i za metu, a to znači da primovanje identitetom obezbeđuje najveće moguće olakšanje u pogledu donošenja leksičke odluke o meti. Pokazuje se da primovanje mete možemo ostvariti i sličnim vizuelnim oblikom, sličnom ortografskim predstavom, sličnom fonološkom predstavom, ili sličnom semantikom prima i mete. Ipak, svi neidentični primovi pokazuju manju jačinu primovanja od one koju obezbeđuje primovanje identitetom. Ukoliko se primovanje mete ne vrši identičnim primom, onda će takvo primovanje postati efikasnim i pouzdanim samo onda, kada se neidentični prim dobro maskira, tako da ispitanik nije u stanju da prim svesno pročita i zapamti, tj. samo onda, kada stimulus prima ne stigne da pobudi svoju procesnu jedinicu u semantičkom (odnosno dugotrajnom) leksikonu. Maskiranje prima ostvarujemo upotrebom vizuelne maske koja se obično sastoji od više jednakih ortografskih znakova u jednom horizontalnom redu (na primer, “#######”). Takva vizuelna maska obično se prikazuje oko 500 ms pre prima i predstavlja tzv. “maskiranje unapred”. Koristi se i “maskiranje unazad”, kada se prvo prikaze prim, a maska dolazi kasnije, tek posle prima. U nekim ogledima vrši se kombinovano maskiranje unapred i unazad uz korišćenje dve vizuelne maske. U protivnom, ako se ne upotrebi vizuelna maska i ako vreme ekspozicije nije kratko, onda stimulus neidentičnog prima može da stigne da pobudi u semantičkom leksikonu neku procesnu jedinicu koja je različita od procesne jedinice mete; onda će ukupni pobudni put prima biti različit od pobudnog puta neidentične mete, pa će olakšanje u procesiranju mete potpuno izostati.
Dalji napredak u smislu razumevanja kognitivnih procesa pri prepoznavanju reči i nereči omogućili su eksperimenti koji su demonstrirali da se može postići pouzdano primovanje mete i onda, kada je prim jedna nereč koja je samo vizuelno slična meti (Forster, Davis, Schoknecht & Carter, 1987). Takav prim ne deli s metom ni leksički status, ni ortografsko-fonološku predstavu, niti semantičku bliskost, a ipak uspeva da sasvim solidno primuje metu. Razmotrimo neke primere takvih slučajeva. Na primer, pretpostavimo da smo reč POTRES odabrali da nam bud meta. Izvršimo „transpoziciju“, tj međusobnu zamenu mesta susednih konsonanata u sredini odabrane mete. Tako ćemo dobiti jednu nereč PORTES koja je vizuelno bliska meti POTRES ali s tom metom osim sličnog vizuelnog oblika nema drugih preklapanja. Eksperimenti su pokazali da maskirani prim PORTES može snažno da primuje metu POTRES. Ili posmatrajmo drugi primer. Umesto transpozicije može se izvršiti „substitucija“, tj zamena jednog slova nekim „tuđim“ slovom; na primer, u reči POTRES substitucijom jednog konsonanta možemo dobiti novu nereč : PODRES, koja takođe može da posluzi kao prim. Važno je uočiti da nereč dobijana transpozicijom (PORTES) kao i nereč dobijana substitucijom (PODRES) zadovoljavaju pravila naše ortografije i fonetike, te kao takve da predstavljaju „legalne“ nereči (napomena: prim nastao substitucijom jednog slova može uspešno da primuje metu samo u slučaju kada je dužina reči veća od 5 slova).
Noviji radovi pokazuju da se primovanje sličnom vizuelnom formom proširuje i na one slučajeve kada se razlika između prima i mete ne svodi samo na jedan slovni znak. Na primer, Peressotti i Grainger (1999) koristili su primovanje s maskiranim primom u zadatku leksičke odluke, a sve to u kombinaciji s primovanjem na bazi sličnosti vizuelnog oblika. Peressotti i Grainger želeli su da ispitaju da li je – u saglasnosti s DRC-modelom – zaista potrebno prisustvo svih slova u primu da bi se pobudili leksikoni. U tom cilju su koristili štampane reči od 6 slova; na primer, reč „BALKON” sluzila je kao meta koju je primovao maskirani prim od 4 slova: BLKN, tj niz konsonanta „izvađenih“ iz mete u originalnom redosledu. Ovakvim primom postigli su pouzdano primovanje mete. Interesantno je da se jednako pouzdano primovanje (Grainger at al., 2006) dobili kada su modificirali maskirani prim ubacivanjem spojnih crtica na mestima izbačenih slova, tj umesto maskiranog prima BLKN koristili su prim: B-LK-N. Ovakav prim bio je potpuno uspešan u primovanju mete tipa BALCON. Međutim, u jednom drugom ogledu zadržali su sve stimuluse nepromenjene, ali u stimulusu za prim permutovali su redosled slova: na primer umesto BLKN koristili su maskirani prim: BKLN ili NLKB. Rezultat je bio poražavajući: od primovanja nije bilo ni traga. Zaključak je bio jasan: mozak može da prepozna reč u kojoj i vise od jednog slova nedostaje, pod uslovom da redosled preostalih slova ostane pravilan, tj. kao u originalnoj reči. Međutim, ako se pravilan redosled slova ispretura, onda mozak nije u stanju da rekonstruiše originalnu reč. Ovi rezultati upozoravaju da princip očuvanja tačne pozicije slova koji je Coltheart primenio u modelu dvojnog puta ne odgovara stvarnosti. Sada je pred istraživačima ozbiljan zadatak da nađu nov algoritam pobuđivanja leksikona koji bi mogao da se koristi pri simulaciji primovanja.
Na kraju ovog razmatranja biće interesantno napomenuti da postupci transpozicije odnosno supstitucije jednog slova u vizuelno sličnom nizu slova, mogu da budu uspešni i kod čitanja normalnog, nemaskiranog teksta. U većini slučajeva, TRASNPOZICIJA SUSENDIH SIBMOLA NE SRPEČAVA PRAVINLU PECREPCIJU NEMAKSIRANE INFOMRACIJE.
DUGOTRAJNO PRIMOVANJE IDENTITETOM
Već je bilo govora o tome da je primovanje identitetom najefikasnija metoda primovanja, jer čitaocu pruža najveće olakšanje prilikom prepoznavanja mete. Pored toga, primovanje identitetom dozvoljava da ispitanik bez vizuelne maske i bez žurbe može da pročita i zapamti prim. Naime, kod dugotrajnog primovanja identitetom cak je i poželjno da prim potpuno aktivira svoju procesnu jedinicu u semantičkom leksikonu, odnosno u dugotrajnoj memoriji. Onda će pobuda aktiviranih puteva u semantičkoj memoriji ostati skoro nesmanjena tokom dužeg vremena. To znači da meta koja se prikaze ispitaniku više sati posle prima, može još uvek da koristi pobuđeno stanje spojnih puteva i procesnih jedinica u leksikonima. Međutim, naš cilj je bio da ispitamo da li se efekat primovanja može sačuvati i u slučaju, kada prim i meta nemaju zajedničku vizuelnu formu ni zajedničku ortografsku predstavu, tj. kada identitet između prima i mete postoji samo u domenu njihove zajedničke fonološke predstave?
Da bismo došli do odgovora na postavljeno pitanje, koristili smo naš nacrt ogleda za identifikaciju vizuelno maskiranih reči (Lukatela, Eaton, Moreno & Turvey, 2007), a kao primove koristili smo reči tipa /harem/, /robot/, .. pisane malim latiničkim slovima. Svaku od tih reči možemo napisati velikim štampanim slovima u bialfabetskoj interpretaciji. Na primer, slovni niz HAPEM za bialfabetskog čitaoca ima 4 moguće fonološke interpretacije: /harem/, /narem/, /hapem/ i /napem/. Samo prva fonološka interpretacija zvuči kao naša reč i predstavlja jedan naš „pseudohomofon”, tj. nereč koja zvuči kao reč. Zaista, za mono-alfabetskog čitaoca slovni niz HAPEM predstavlja nereč koja se nikada ne pojavljuje u našem korigovanom tekstu. Pored ovakve pseudohomofonske mete, koristili smo kao metu još i kontrolni niz velikih štampanih slova tipa HATEM koji predstavlja nereč i u fonološkom i u ortografskom smislu.
Ogled je bio rađen u 2 faze (faza učenja i faza testiranja), a ispitanici su bili podeljeni u 4 grupe. Tokom faze učenja, jedna polovina ispitanika imala je priliku da bez žurbe prouci jednu polovinu od svih test reči koje će biti mete u drugoj fazi ogleda. Slično tome, druga polovina ispitanika videla je i proučila drugu, komplementarnu polovinu test reči. Sve test reči u fazi učenja bile su napisane malim slovima i nisu bile maskirane. Posle jednosatne pauze, ispitanik se vraćao u laboratoriju da bi uradio test fazu ogleda. Ispitanik je imao zadatak da brzo identifikuje i glasno pročita metu koja je bila pokrivena jakim vizuelnim sumom. Ulogu vizuelnog suma odigrao je pseudoslučajni složaj svetlih tačkica koje su bile gusto rasute preko mete. tako da je verovatnoća pravilne identifikacije mete bila oko 0,5. Kada kažemo „pravilna identifikacija” podrazumevamo da će ispitanik glasno pročitati /harem/ i onda, kada na ekranu stvarno piše: HAREM, ili HAPEM, ili HATEM.
Glavni rezultati ovog ogleda predstavljeni su na Slici 4. Ispitanik iz prve grupe (koji je u prvoj fazi ogleda već video prim tipa /harem/), u fazi testiranja pravilno je identifikovao metu tipa HAREM s prosečnom proporcijom pogodaka .49; ispitanik iz druge grupe (koji prethodno nije video prim tipa /harem/), u fazi testiranja pravilno je identifikovao metu tipa HAREM s prosečnom proporcijom pogodaka .21. To znači da je veličina primovanja mete HAREM bila (.49 - .21) = .28. Slično zaključujemo da je veličina primovanja pseudohomofonske mete tipa HAPEM dostigla .26, dok je veličina primovanja mete HATEM bila svega .07. Ne zaboravimo da se ovde radilo o veličini primovanja identitetom koji je fizički postojao samo za parove tipa „reč – reč“ (kao na primer, harem-HAREM). Međutim, za parove tipa „reč - pseudohomofonska nereč“ (kao na primer harem-HAPEM) identiteta više nije bilo, ali veličina primovanja bila je ipak značajna. Tek za parove tipa „reč - prava nereč“ (harem-HATEM) uspešnost identifikacije mete naglo je opala i postala statistički beznačajna.
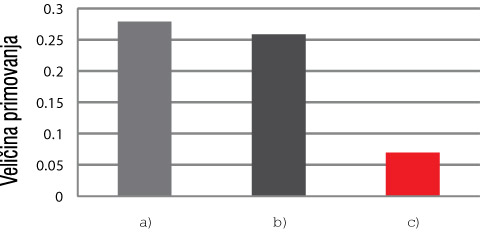
Slika 4. Dugotrajno primovanje identitetom. Rezultati ogleda za 3 tipična para „prim-meta“: (a) vizuelni identitet, (b) fonološki identitet i (c) vizuelno različiti i fonološki različiti.
Rezultati ovog ogleda ubedljivo pokazuju da mentalni procesi kod dugoročnog primovanja koriste fonološke kodove. Sve dok meta i prim imaju identičnu fonološku interpretaciju (kao u slučaju parova harem-HAREM ili harem-HAPEM), dugoročno primovanje je uspešno. Kada se fonološka sličnost izgubi (kao u slučaju parova harem-HATEM) dugoročno primovanje iščezava. Mogućnost da se ovde radi o primovanju sličnim vizuelnim oblikom a ne fonologijom, isključena je činjenicom da se pseudohomofonska nereč tipa HAPEM i legalna nereč tipa HATEM u ortografskom smislu jednako slicne legalnoj reči HAREM (razlika je samo u jednom slovu na istoj slovnoj poziciji). Prema tome, između meta HAPEM i HATEM ne bi smelo da bude razlike ako bi primovanje bilo na ortografskoj bazi; međutim, rezultati pokazuju da razlika postoji i da je izuzetno velika.
ZAKLJUČAK
U ovom članku upoznali smo neke osobine jezika koje mogu da utiču na kvalitet prijema i na prepoznatljivost pisanih telekomunikacionih poruka. Tako, na primer, pokazuje se da brzo (tj. tokom jedne fiksacije oka) prepoznatljive poruke ne treba da sadrže više od 7 odvojivih elemenata informacije, pri čemu pojam „elementa informacije“ može da obuhvati različite podskupove informacija u sastavu jedne informacione celine; na primer, „element informacije“ može da bude jedna cifra, ili jedan broj sa malo cifara, ili jedan slovni znak, ili jedna kratka reč.
U članku smo pokazali da ljudski mozak, pri obradi primljene pisane poruke, obavezno koristi fonološke kodove i da konverzija ortografskih kodova u fonološke kodove nije trenutna, nego traje relativno duže vreme. To znači da pisane poruke, postaju razumljive tek nakon što se pisani simboli (tj. grafemi) pretvore u fonološke simbole. Ako poruka sadrži slova koji se mogu konvertovati u foneme na dva različita načina, tj. ako je poruka fonološki dvoznačna, onda takvim porukama treba dati dovoljno vremena za konverziju kodova.
U posebnim slučajevima kada se pisane poruke prikazuju izuzetno kratko (na primer, podnaslovi u stranim filmovima, prevodi razgovora sa strancima „uživo“ na TV, itd.) i kada korisnik informacija ne može sa sigurnošću da identifikuje ni fonološki jednoznačne reči, dolazi do pojave nenamernog primovanja vizuelno sličnim rečima koje je korisnik ranije video u nekoj prethodnoj poruci. Takvo nenamerno primovanje moglo bi ozbiljno da izmeni smisao primljene poruke. Srećom, postoji jednostavan način da se nenamerno primovanje izbegne: prikazivanje poruke treba produžiti onoliko koliko je potrebno da slovni znaci u svakoj poruci postanu pouzdano prepoznatljivi.
Literatura
[1] Coltheart, M: “Lexical access in simple reading tasks”, in Underwood, G. (Ed.), Strategies of information processing, Academic Press, New York, 1978, pp. 151–216.
[2] Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J.: “DRC: A Dual Route Cascaded Model of Visual Word Recognition and Reading Aloud”, Psychological Review, 108, 2001, pp. 204-256.[3] Forster, K. I., Davis, C.: “Repetition priming and frequency attenuation in lexical access”, Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 1984, pp. 680-698.
[4] Forster, K. I., Davis, C., Schoknecht, C., & Carter, R.: “Masked priming with graphemically related forms: Repetitition or partial activation?”, The Quarterly Journal of Experimental Psychology, 39A, 1987, pp. 211-251.
[5] Lukatela, G., Savić, M. D., Gligorijević, B., Ognjenović, P. i Turvey, M.T.; “Bi-alphabetical lexical decision”, Language and Speech, 22, 1978, pp. 142-165.
[6] Lukatela, G., Savić, M. D., Ognjenović, P. & Turvey, M.T. “On the relation between processing the Roman and the Cyrillic alphabets. A preliminary analysis with bi-alphabetical readers”, Language and Speech, 21, 1978, pp. 113-141.
[7] Lukatela, G., Statistička teorija telekomunikacija i teorija informacija, Građevinska knjiga, Beograd, 1981.
[8] Lukatela, G., Eaton, T., Lee, C., Carello, Claudia & Turvey, M. T.: “Equal homophonic priming with words and pseudohomophones”, Journal of Experimental Psychology: Human Perception and Performance, Vol. 28, No. 1, 2002, pp. 3-21.
[9] Lukatela, G., Eaton, T., Moreno, M. & Turvey, M. T.: “Equivalent inter- and intramodality long-term priming: Evidence for a common lexicon for words seen and words heard”, Memory & Cognition, 35 (4), 2007, pp. 781-800.
[10] Lukatela, G., Moreno, M., & Turvey, M. T.; “On the long-term bi-alphabetical priming by phonological identity”, (in press).
[11] Peressotti, F. & Grainger, J.: “The role of letter identity and letter position in orthographic priming”, Perception and Psychophysics, 61, 1999, pp. 691-706.